Bots, crawlers en spiders. Hoe beperk je overlast?
Zoekmachines doorzoeken constant uw website om pagina’s op de juiste rangorde te schikken. Echter kan dit voor overlast op uw website zorgen door constante monitoring van de zoekmachines. Wij bespreken hier hoe de overlast beperkt kan worden zodat de performance van uw website een boost in de goede richting krijgt.
Bots met kwade bedoelingen
Ook kan een website te maken krijgen met zogenaamde “bad bots”. Deze bots zijn vaak ontwikkeld door mensen die minder goede intenties hebben. Zo bestaan er bots die versienummers van veelgebruikte pakketten zoals WordPress, Magento, Prestashop, phpBB, vBulletin of phpMyAdmin uitlezen. Wanneer kwetsbare versies gevonden worden dan kan dit leiden tot aanvallen op de desbetreffende website of er wordt geprobeerd ze onderuit te halen. Of ze zijn op zoek naar e-mailadressen op een website zodat er vervolgens spam naar toe gestuurd kan worden.
Methodes voor beperking overlast op uw website
De meeste goedwillende zoekmachines bepalen zelf de frequentie van het bezoeken/indexeren van een website. Mocht er onverhoopt toch een probleem optreden dan is het mogelijk om dit op verschillende manieren op te lossen. Het gedrag van bots kan gelukkig beïnvloedt worden door een site-eigenaar of webbouwer. Hoe u dit doet bespreken wij hieronder.
robots.txt
Niet elke zoekmachine heeft een controlepaneel. Om de indexatie van een website toch enigszins te kunnen sturen is het “The Robots Exclusion Protocol”, oftwel “robots.txt” uitgevonden. Het bestand “robots.txt” is een tekstbestand op een website die instructies voor zoekmachines kan bevatten. Dit bestand staat in de webroot van een website en bevat doorgaans instructies die aangeven welke bestanden en mappen door zoekmachines geïndexeerd mogen worden. Of juist niet, want pagina’s uitsluiten is ook een optie. Omdat het een de-facto standaard betreft kan de interpretatie verschillen. Zo maken Bing en Majestic-12, in tegenstelling tot Google, gebruik van de “Crawl-delay” opdracht. Met behulp van deze opdracht in de robots.txt kan men dus vanuit de website de indexatie beïnvloeden.
De opdracht kent de volgende mogelijkheden:
| Geen waarde opgegeven | Normaal |
| 1 | Langzaam |
| 5 | Heel langzaam |
| 10 | Extreem langzaam |
Individuele bots in robots.txt beïnvloeden:
User-Agent: MJ12bot
Crawl-Delay: <waarde>
User-agent: msnbot
Crawl-delay: <waarde>
Het bovenstaande plaats je dus in een tekstbestand op de website. Het kan voor komen dat er al een bestand met regels aanwezig is. In dat geval kan je “crawl-delay” toevoegen aan de bestaande uitzonderingen.
Een vertraging opgeven voor alle bots/crawlers in robots.txt:
User-agent: *
Crawl-delay: <waarde>
Googlebot
Meestal is het niet wenselijk om de bot van Google te blokkeren, het is tenslotte wel één van de meest gebruikte zoekmachines. Google respecteert regels uit robots.txt, maar doet verder niets met de “Crawl-Delay” optie.
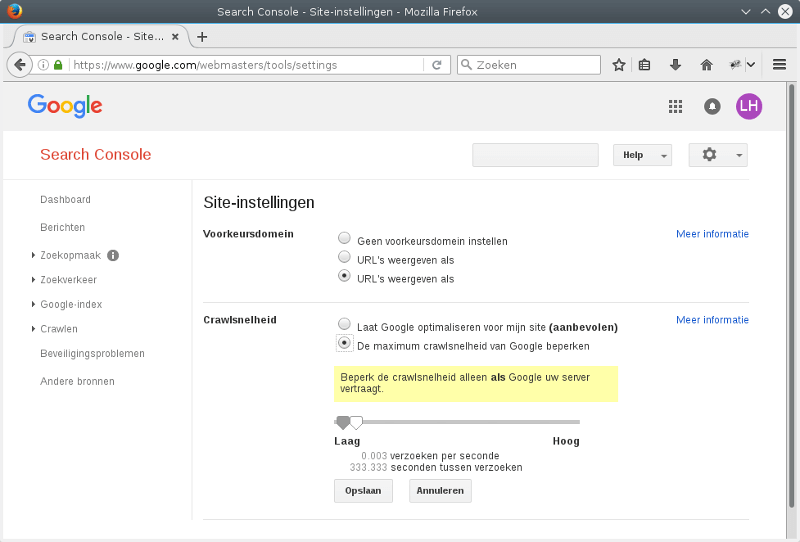
Het aanpassen van de frequentie kan in dit geval via de Google Search Console. Wanneer u nog niet bekend bent met de werking of het nut van de Google Search Console, dan is dit een goed startpunt: Google Webmasters.
Wanneer een site (“property”) is aangemaakt, dan is het mogelijk om via de “Site-instellingen” de crawlsnelheid aan te passen. Een SEO specialist kan hulp bieden om de juiste snelheid te bepalen.
WordPress
Er zijn Plugins voor platformen (WordPress) beschikbaar die bots blokkeren. Dit beïnvloedt niet de manier van indexeren maar kan een uitkomst bieden voor ongewenste bots. Goeie plugins om dit uit te voeren zijn “Blackhole for Bad Bots” en “StopBadBots“.
Er zijn hierin dus veel mogelijkheden om overbelasting tegen te gaan. Plugins zijn een perfecte oplossing als u een platform gebruikt die dit aanbiedt. Daarnaast kan uw robots.txt tekst aangepast worden zodat u het maximale kan halen uit de indexatie van de genoemde zoekmachines. De invloed van uw robots.txt kan ook uw SEO bevorderen. Kijk daarom goed naar uw robots.txt tekst en pas deze zo nodig aan voor optimaal resultaat.
Plesk servers
Op onze Plesk servers kunt u bots blokkeren via een .htaccess bestand. Dit stukje script staat op GitHub: Bad Bot Blocker.
Bots blokkeren met High Performance hosting
Op onze high performance managed webhosting servers blokkeren wij standaard al een groot gedeelte van de bad bots en hier hoeft u dus niets voor te doen. Onze hosting experts staan voor alle vragen omtrent bots, crawlers en spiders voor u klaar. Neem gerust contact met ons op om hierover in gesprek te gaan.
Bronnen
http://www.majestic12.co.uk/projects/dsearch/mj12bot.php
https://blogs.bing.com/webmaster/2009/08/10/crawl-delay-and-the-bing-crawler-msnbot/
http://www.robotstxt.org/